
The Answer Most Teams Miss
If Google isn't indexing your React/Next.js site properly, the problem is rarely 'JavaScript support.'
It's crawl budget leakage caused by crawl traps + inefficient rendering paths.
In modern SPAs, Googlebot discovers far more URLs than you intend, queues JavaScript rendering asynchronously, and prioritizes crawl paths based on perceived value. If your architecture generates infinite URL states, you're effectively telling Google:
"Waste your crawl budget here."
Key Takeaways
- React doesn't break SEO — poor architecture does
- Crawl traps are the #1 silent killer of indexation in SPAs
- Server logs reveal what tools (Screaming Frog, GSC) can't
- Internal linking is more powerful than most dev-level fixes
- Rendering strategy (SSR vs CSR) determines crawl efficiency
- robots.txt stops crawling, but canonicals and linking fix indexing
What's Actually Happening Under the Hood
Googlebot's Two-Phase Processing (Why React Breaks Things)
| Phase | What Happens | The Problem |
|---|---|---|
| 1. Initial Crawl (HTML fetch) | Googlebot downloads the raw HTML | CSR apps ship near-empty HTML — critical content is missing |
| 2. Deferred Rendering (WRS queue) | JavaScript is executed later in a queue | Rendering is delayed; high-volume sites may never get fully rendered |
The result: Partial indexing, stale cached content, and important pages that never get fully rendered.
The Core Issue: Crawl Traps in JavaScript Architectures
What is a Crawl Trap?
A crawl trap is any URL pattern that creates unbounded crawl paths — effectively infinite pages that Googlebot can discover.
Common offenders in React/Next.js:
- Faceted navigation (filters, sort, pagination)
- Parameterized URLs (?sort=, ?filter=, ?page=)
- Calendar / date pickers generating URLs
- Infinite scroll with crawlable URL states
- Client-side routing that exposes hidden states
Example — a single product listing with 3 filters creates:
/products?category=fitness&price=low&sort=asc
/products?category=fitness&price=low&sort=desc
/products?category=fitness&price=high&sort=asc
...and hundreds more combinationsMultiply that across all filter combinations → thousands of near-duplicate URLs with zero unique value.
Why This Destroys Crawl Budget
| Issue | Impact |
|---|---|
| Discovery explosion | Internal links + JS interactions expose combinatorial URLs |
| Rendering queue bottleneck | Googlebot queues JS rendering — low-priority pages never get processed |
| Index dilution | Thin/duplicate URLs compete with core pages for crawl equity |
| Crawl prioritization shift | Google reallocates crawl budget away from your important revenue pages |
How to Diagnose Crawl Traps (Step-by-Step)
Step 1: Google Search Console → Crawl Stats
Look for: High crawl requests with low indexing rate, spike in 'Discovered – currently not indexed' status, and large response volumes concentrated on low-value URLs.
Step 2: Server Log Analysis (Non-Negotiable)
This is where the truth is.
Most teams skip this. Server logs show exactly which URLs bots are visiting, how often, and at what depth. What to extract:
- Most crawled URLs (ranked by bot request frequency)
- Parameter frequency (which query strings bots hit most)
- Crawl depth patterns (how deep bots are going)
Red flags: Bots spending time on filtered URLs, deep crawl paths with no business value.
Step 3: Full Crawl (Screaming Frog / Sitebulb)
Configure to render JavaScript. Identify: parameterized URL clusters, infinite crawl paths, duplicate page templates. Cross-reference with GSC indexing status.
Step 4: URL Pattern Mapping
Group all discovered URLs by parameters, templates, and search intent. Goal — separate into 3 buckets:
- Index-worthy pages (canonical, unique, valuable)
- Crawl-only utility URLs (useful but shouldn't be indexed)
- Pure noise (block entirely via robots.txt)
Fixing the Problem (What Actually Works)
Layer 1: robots.txt — Stop the Bleeding
Part of any comprehensive technical SEO audit starts with blocking non-essential parameters from being crawled entirely.
User-agent: *
Disallow: /*?sort=
Disallow: /*?filter=
Disallow: /*?session=
Disallow: /*?ref=Important nuance: robots.txt controls crawling, not indexing. You still need canonical and internal link fixes.
Layer 2: Canonicalization — Signal Consolidation
Ensure all parameter variations point to a single canonical URL. The mistake to avoid: self-referencing canonicals on filtered pages, which does nothing to consolidate link equity.
Layer 3: Internal Linking Control
Your biggest lever.
- Remove crawlable links to filtered states from your HTML
- Use JS-triggered interactions (onclick) instead of anchor tags for UI-only filters
- Ensure only indexable pages appear in your HTML navigation
Layer 4: Rendering Strategy (Critical for React)
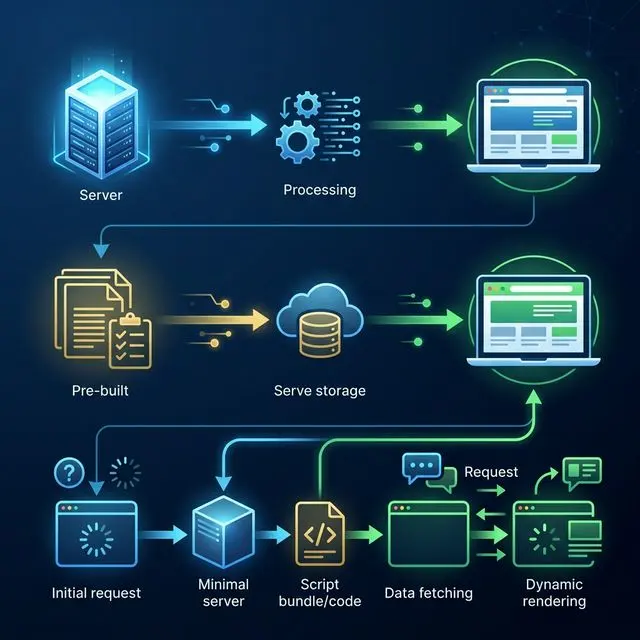
SSR vs SSG vs CSR rendering strategies — which to use for SEO
| Strategy | Best For | SEO Benefit |
|---|---|---|
| SSR (Server-Side Rendering) | Critical landing pages, dynamic content | Immediate HTML availability for Googlebot |
| SSG (Static Generation) | Stable, evergreen content | Fastest crawl and index, zero render delay |
| Dynamic Rendering | Legacy CSR apps, complex SPAs | Serve pre-rendered HTML to bots; CSR to users |
| Pure CSR | App-like features (dashboards) | Avoid for SEO-critical pages entirely |
Rule: If it matters for SEO → don't rely purely on CSR.
Layer 5: Structural Siloing
This is core to website architecture planning — ensuring Google understands page hierarchy and prioritisation.
- Establish clear hierarchy: category → subcategory → detail
- Limit cross-linking between unrelated filter states
- Keep crawl depth shallow for key revenue pages (≤ 3 clicks from homepage)
Layer 6: Core Web Vitals Optimization
Slow rendering = lower crawl efficiency = fewer pages processed per crawl cycle. Key metrics to target:
- LCP (Largest Contentful Paint) → content visibility speed
- INP (Interaction to Next Paint) → interaction responsiveness
Improving these directly increases how many pages Googlebot can process in each crawl window.
Real-World Case: FITPASS
The Problem:
- React-based architecture with massive filter combinations
- Crawl budget wasted on hundreds of low-value parameterized URLs
- Critical revenue pages under-crawled and inconsistently indexed
- Mobile performance score of 32 — extremely poor rendering efficiency
What We Fixed:
1. Blocked parameter crawl paths via robots.txt — immediately cut crawl waste.
2. Removed crawlable links to filter states — stopped bots following parameterized URLs from navigation.
3. Implemented SSR for key landing pages — ensured immediate HTML availability for membership and subscription pages.
4. Consolidated duplicate URL patterns — merged thin parameter variants into canonical pages.
5. Optimised Core Web Vitals (LCP + INP) — reduced rendering time to improve crawl efficiency per session.
Results:
- Crawl waste reduced significantly — bots now focus on revenue pages
- Indexation improved consistently across priority pages
- Mobile performance: 32 → 70
- Clear shift in crawl focus toward high-value landing pages
Ready to Fix Your Crawl Architecture?
If your React or Next.js platform isn't indexing properly, a comprehensive technical SEO audit will identify exactly where crawl budget is being wasted — at the codebase and architecture level, not just surface fixes.
I work directly with engineering teams to diagnose crawl inefficiencies, implement rendering fixes, and rebuild URL architectures for reliable, scalable indexation.
Frequently Asked Questions
Why does Google struggle with React websites?
Most React apps rely heavily on client-side rendering. Google processes JavaScript in a delayed rendering queue, which can prevent timely indexing of content if HTML isn't available upfront.
What is the biggest crawl budget issue in SPAs?
Faceted navigation and parameterized URLs creating infinite URL combinations. These consume crawl resources without adding unique value, preventing important pages from being crawled efficiently.
Is SSR mandatory for SEO in React?
Not always, but for critical pages, SSR or SSG significantly improves crawlability and indexing reliability compared to pure CSR implementations.
Can robots.txt fix crawl traps completely?
No. It stops crawling but doesn't consolidate signals. You still need canonical tags and internal linking cleanup to fully resolve the issue.
How do I know if Googlebot is wasting crawl budget?
Check server logs and Search Console crawl stats. If bots frequently hit parameterized or low-value URLs, you have crawl inefficiency.
Does infinite scroll affect SEO?
Yes, if it generates crawlable URL states or hides content behind JS without proper pagination or SSR fallback.
What tools are best for diagnosing JavaScript SEO issues?
Server log analysis, Screaming Frog with JS rendering, and Search Console crawl stats together provide the clearest picture of crawl behavior.
Can improving Core Web Vitals increase crawl efficiency?
Indirectly, yes. Faster rendering and interaction improve how efficiently Googlebot processes pages, especially in JS-heavy environments.